
A lot of us have felt annoyed and awry because of the pop-ups that appears when you try to access a site via Google Chrome, which asks you to confirm whether you are human or not. For once it seems like the most stupid thing to ask, especially if it’s popping up on your face again and again. That is CAPTCHA, a challenge-response test that allows the browser to determine that it’s not some machine which is trying to get into your personal searches. CAPTCHA has become a common protective measure to keep spam bots off the internet and prevent abuse.
But in recent years, CAPTCHA has been expanded and has also become an intricate task requiring us to concentrate on the so-called response challenge. Why does your browser is asking you to confirm “I am not a robot”? And how it just transitioned into an annoying and time-consuming challenge? Read how something that started as a tool for removing spambots, has now become a grueling race between humans and machines.
What is CAPTCHA?
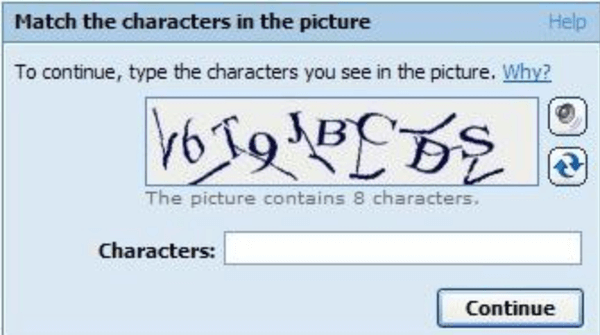
CAPTCHA stands for Completely Automated Public Turing Test. It was developed sometime in the early 2000s as a test for humans to prove that they are not machines or spam bots trying to breach browser security. Though the inventorship of CAPTCHA is a matter of another debate, its earliest version is dated back to 1997. When it was first used, CAPTCHA used to ask users to prove their “humanity” by typing a sequence of distorted letters in simple text. In some sequences, the distorted letters were combined by numbers written in similar distorted format.
These characters were written in a way that there seemed no space between them and the code was changed on every login attempt. This was done because, in order to decode an almost infinite number of distorted sequences, some human intelligence would always be required; whereas, a computer machine algorithm cannot detect distorted sequences. Thus, CAPTCHA was instantly adopted by many web and mail service providers.
But then in the next few years, CAPTCHA got complicated.
Google’s reCAPTCHA: A Complicated Upgrade to the Original Test

In 2007, Google bought the program called reCAPTCHA from a group of original researchers of the system and started using it extensively in Google Scholar and Google Books. But, from where it had begun, CAPTCHA in this latest form became a headache for Google users. As the research on machine learning grew, so did the capability of computing systems and their algorithms to solve intricate problems. Thus, the original character sequences became too easy for bots and machines to solve. So, Google went ahead and made those characters more twisted and technically more confusing to human eye. This actually started the real race between human and machine intelligence, which transitioned into the real annoyance reCAPTCHA became for Google users. To make sure that the user accessing Google platforms and searches is not some bot, Google made the sequences more difficult to solve.
Adding Images to the Test: Google’s No CAPTCHA reCAPTCHA
In 2014, a lot late after Google acquired reCaptcha, it decided to act upon the annoyance its sequences were causing it to the users. Plus, in all these years, once again the researchers in order to create smarter machines have outmatched reCAPTCHA’s capabilities of understanding response challenges. In an experimental test, Google researchers determined that despite utmost complications and annoying popups, the machine learning algorithms were able to get more than 99 percent of the responses correctly while we humans barely managed 33 percent. So, it was time for a change.
Google decided to make users’ annoyance go away. The new “NoCAPTCHA reCAPTCHA” allowed users to just pass on the test by clicking on the tick box. This time Google went way ahead with API technology and used user preferences to determine if its a human or a robot. Google’s new reCAPTCHA analyzed user searches, as well as the movement of the mouse cursor. A bot can’t emulate a mouse click as for a bot, analyzing the code for that particular CAPTCHA test would see that virtual tick box as a graphic image, and would not respond to that. But again, if a bot can read JavaScript, then it can easily emulate that and the mouse movement tracking option would fail.
So how you get that issue right? And, what if you made a different search from your preferences?

Well, in that case, welcome to another test. Google’s new reCAPTCHA takes you to a series of “eye-tests” to see if you are a human or a robot. So, in case you make an unreferred or suspicious search, Google would ask you to choose some specific images from a whole group of them. We all have noticed Google asking us to identify pictures with traffic lights, cars, parks, or road signs, right? That’s what NoCAPTCHA reCAPTCHA is.
This is the most updated and most widely used version of CAPTCHA, which is used as a medium of human-AI distinction by not only Google but platforms like Twitter, Facebook, and Craigslist to prevent spam and abuse of social media profiles of users. But once again, the pictures in this version have become blurrier to human eyes, increasing the complicacy of the puzzle, and has again come across the same path reCAPTCHA went before.
But Why?
 What's More Secure? Fingerprint Recognition vs Facial RecognitionBoth Fingerprint Touch and Face Unlock have become major phone security features and are constantly compared over their effectiveness. Know...
What's More Secure? Fingerprint Recognition vs Facial RecognitionBoth Fingerprint Touch and Face Unlock have become major phone security features and are constantly compared over their effectiveness. Know...Why CAPTCHA Puzzles are so Complicated?

CAPTCHA was started as a medium to prevent bots and machines to imitate as human user and access any kind of data for wrongful means. But as the research and experiments on machine learning and artificial intelligence went too far and even were successful, we created machines with capabilities of solving much complex computations and CAPTCHA became a piece of cake. Science gave machine such extensive abilities, that now if we try to make something hard for software or bot, it would become harder for a human being to decode.
Is it too Much of a Surprise that CAPTCHA is Somehow Failing?

Definitely not. We have created functional quantum computers. We have solved hundreds of puzzles and computation problems regarding financial analysis, business decisions, and medical sciences. We have made use of tons of machine-based applications and tools to ease our lives and help us in more complex research areas. And in the meanwhile, we have given the machines their own intelligence to increase task speed and efficiency. Since our lives are so much dependent on AI and machine learning, it was just a matter of time that it surpasses us.
What Length may CAPTCHA can Go Further?

As per what researchers are getting into with this response-challenge mechanism, this is just the beginning. There have been various tests to upgrade the current CAPTCHA tools and change the way these response challenge-tests are conducted. In 2017, PayPal obtained a patent over a new sort of CAPTCHA technique.
Here, the puzzles and questions asked to a user to prove his/her humanity would differ as per their ethnicity, location, and gender. Similarly, Amazon Technologies patented a CAPTCHA puzzle style, where people would be asked to solve optical illusions and typical logic puzzles, that would be non-familiar to them. Now, here Amazon tried to reverse the puzzle.
Amazon Technologies has claimed that most humans would get such responses wrong, while the modern AI, given its capabilities, would get it right, and therefore, the response with the wrong response would be the human user. Other patents include game-like puzzle for CAPTCHA, where the users would require solving board puzzle sort of images to prove their humanity. These are some of the initial ideas that are getting their way to update CAPTCHA.
But, Are They Really Effective?

In many ways, they are not. Firstly, in this “space-age” generation where machine learning is literally the next step in human evolution, no CAPTCHA would remain unbroken. -Secondly, these ideas are too complicated for humans. If you expect a guy to answer culturally diverse question correctly all the time, then you’re wrong. People differ from each other in ethnicities, language, and personalities at a very large scale and it’s nearly impossible to develop such an extensive set of response-challenges based on cultural background. Moreover, the internet is something, which is accessible to anyone from anywhere regardless of that person’s IQ, age, and intelligence level. So, it’s hard to believe that every person of every age would have it in him to solve a board game puzzle to pass a web page. Probably, researchers, in order to sustain a resistance against machine interference have forgotten what it’s like to be a human and have just removed that factor from their recent developments.
What can be Done to Make CAPTCHA More Reliable?
Well, that is a subject of a great discussion and research before we could come up with something that would make this easier for humans. However, there is a need to look for some aspect of human behavior that may be impossible for an AI bot to mimic. More focus can be diverted to developing CAPTCHA tools that would look for webpage “actions”. Google recently activated its Version 3 of reCAPTCHA called reCAPTCHA v3.
The new version of the response-challenge test by Google use what’s called “Adaptive Risk Analysis”, which do not push users to any sort of test and don’t ask them for ticking up the virtual box. It’s completely friction-free for users and allows them to access webpages directly. To carry out bot detection for preventing spam abuse, Google’s new reCAPTCHA would allow website owners to determine whether their site users are a bot or not, via scores that Google would give them based on its risk analysis algorithm. The score would detect if the traffic on the site is suspicious or not.
Owners can then present suspicious users with a response test to cross-check reCAPTCHA’s detection. While Google won’t tell how their new algorithm would assign these scores to users, it can be considered as a welcoming medium of filtering traffic, where users’ annoyance and difficulty to solve the earlier tests has been considered.
Final Opinion

It’s too early to say that Google’s new reCAPTCHA v3 is the best and most user-friendly way to avoid bot traffic on webpages. Moreover, the pace at which AI and machine learning research are moving ahead, we cannot know of implications that would have on any new CAPTCHA technique.
Since people are putting more stakes at machine learning and not on surveillance on machine activities, all these new patents of CAPTCHA techniques may become non-viable in the near future. For now, CAPTCHA remains the most widely used response-challenge test for bot detection on the web. But to have it that way for more and more years, it is important that methods of the distinction between AI and humans are discovered before we pass on everything we have and whatever defines our legacy to the smart machines we are being dependent on.